Gallery
No video available.


写 Shader 总是感觉在盲写,最近试着把 GPU 内部流程具象化成一个“仪表盘”。这就当是我的学习笔记,通过“分阶段点灯”的方式,梳理数据从 Draw Call 到屏幕成像的全过程,并把 Unity 和 Unreal 的管线对号入座。
以前写 着色器 (Shader) 的时候,我经常是一种“盲写”的状态。代码抄过来,放在 v2f 里能跑,放在 frag 里也能跑,但你要问我这行代码到底是在显卡的哪个角落运行的?它的代价是什么?我往往答不上来。
比如,当我看到一个透明气泡材质时,我潜意识里不仅看到了它的颜色,还看到了它背后疯狂运转的管线压力:
// 学习笔记:透明气泡的配置
// 这种材质的压力主要在片元阶段 (Frag) 和输出合并阶段 (OM),因为要处理混合。
<ShaderPipeline
stages={PIPELINE_RASTER}
modifiedStages={['frag', 'om']}
label="VISUAL_TARGET::TRANSPARENT_BUBBLE"
/>当 片元着色器 (Fragment Shader) 和 输出合并 (Output Merger) 的灯同时亮起,这就意味着:大量的像素计算 + 混合叠加。这就是为什么美术同学随便放几个透明特效,帧率就掉得妈都不认的原因。
为了治好这种“虚”的感觉,我强迫自己在脑子里建立了一个 “GPU 状态仪表盘”。每当数据流过管线,对应的模块灯就会亮起。这篇复盘,就是我试图把这个脑内仪表盘具象化的过程。
在深入细节之前,我得先纠正自己以前的一个误区:GPU 不是一个可以随意指挥的“多面手”,它更像是一个签了死合同的流水线工厂。
这个工厂里有几千个工人(Core),为了让他们同时干活不打架,GPU 制定了一套不可逆的 “数据契约”:
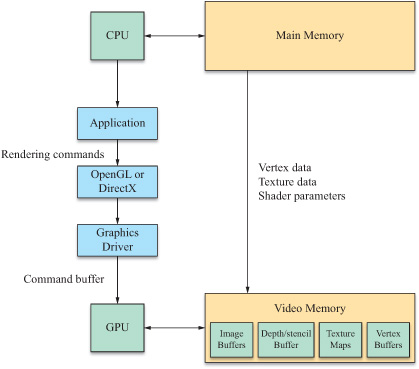
一切的开始,并不是 GPU,而是 CPU。
CPU 得先把所有家当——模型顶点、法线、贴图、Shader 代码——统统搬进显存 (VRAM)。然后设置好状态(比如:“我现在要开深度测试了啊!”),最后吼出那句最重要的咒语:Draw Call。
复盘点: 以前总听说 CPU 瓶颈,现在懂了。Draw Call 这东西很贵,如果 CPU 在一帧里喊了几千次“画这个!”,GPU 可能会一脸懵逼地问“就这?没吃饱啊”,而 CPU 已经累吐血了。
数据终于进显卡了。这时候,仪表盘的前端亮了。
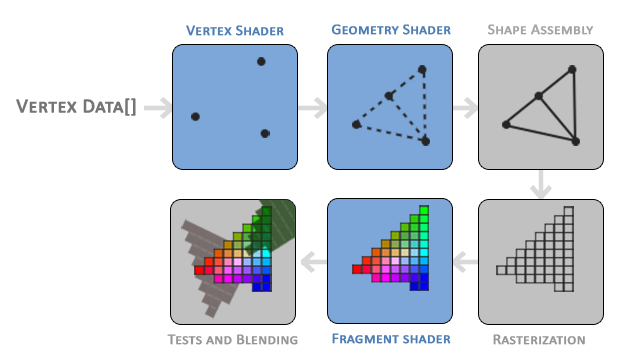
输入装配 (Input Assembler): GPU 像个不知疲倦的搬运工,从显存里读取顶点数据,根据索引把它们“组装”成一个个独立的三角形。
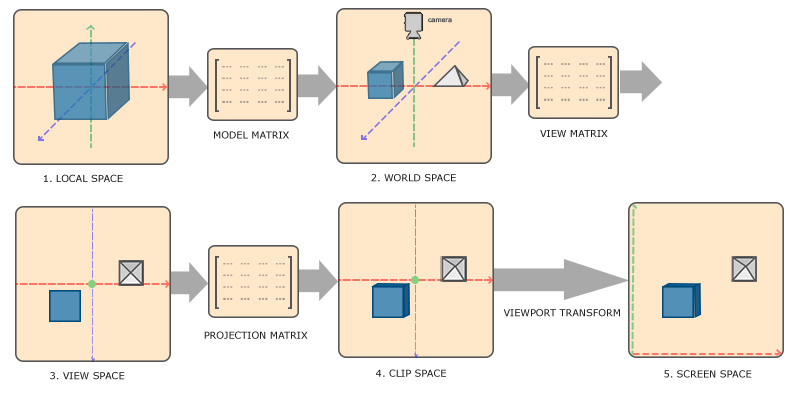
顶点着色器 (Vertex Shader):【绝对主角】 这是我们写 Shader 最常接触的地方。它的核心任务只有一个:坐标变换。
这个过程就像《盗梦空间》里的层级穿越:
在这个阶段,其实还有两个很容易被忽视的功能,它们默认是 OFF 的:
曲面细分 (Tessellation): 开启后,GPU 会在两个顶点之间“无中生有”出更多三角形。
几何着色器 (Geometry Shader): 它拥有更疯狂的权限——它可以凭空把一个点变成一个草丛(生成新的图元)。
这是从 3D 到 2D 的质变。几何体被“拍扁”了,准备变成像素。
生成片元 (Fragment Generation): GPU 扫描三角形,找出它覆盖了屏幕上的哪些格子。
插值 (Interpolation): 这是硬件自动完成的魔法。顶点是红色的,底边是蓝色的,中间的渐变色就是这一步通过 重心坐标 (Barycentric Coordinates) 算出来的。
背面剔除 (Backface Culling): 虽然通常默认是 ON,但画双面旗帜、树叶时,我们需要手动关掉它,否则背面就是透明的。
裁剪测试 (Scissor Test):【默认 OFF】 这不同于视锥体裁剪。它是一个强制的矩形框,框以外的像素直接不画。UI 系统(比如 UGUI)做滚动列表时,就是开这个开关来实现遮罩的。
这是仪表盘最后端亮起的时候,也是显卡最烫、风扇转得最快的时候。
片元着色器 (Fragment Shader):【绝对主角】 这里是计算光照、采样贴图的主战场。屏幕有多少像素,这段代码就要跑多少遍(甚至更多)。因为计算量大,这里通常是性能瓶颈的重灾区。
输出合并 (Output Merger): 这是最后一道关卡,决定片元是“画上去”还是“被丢弃”。
这里有一个我以前一直忽视,但其实非常强大的功能:
模板测试 (Stencil Test):【默认 OFF】 每个像素除了有颜色和深度,还可以有一个 0-255 的整数标记(Stencil Value)。
1,并不输出颜色(ColorMask 0)。然后再画另一个物体时告诉 GPU:“只在模板值等于 1 的地方画”。这就相当于在屏幕上挖了一个专门的通道,让你可以精确控制哪里的像素该显示。理解了上面三个阶段,再看 Unity 和 Unreal 的区别,其实就是它们控制这些灯亮起的顺序和频率不同。它们是在用软件逻辑指挥这套硬件契约。
为了看清楚它们的区别,我决定用仪表盘一步一步地跟踪它们的数据流。
URP 的核心虽是前向渲染,但它经历了一次巨大的战术升级。我们要区分 传统 Forward 和 Forward+ (分簇渲染)。
GPU 拿到模型顶点,在 Vertex Shader 里把它从模型空间变换到屏幕空间。这时候数据还是几何形态。
这一步在硬件内部瞬间完成,三角形变成了无数个待处理的片元。
这是 URP 最累的一步,也是 Forward+ 展现魔法的地方。
传统 Forward (旧版):
逻辑非常“憨”。Fragment Shader 拿到像素后,会把场景里所有的灯(比如 8 盏)挨个算一遍。哪怕这盏灯在背后,甚至根本照不到我,它也得跑一遍 dot(N, L)。这导致灯光数量受限严重。
Forward+ (新版 URP): 它是带“地图”的 Forward。
在 Fragment Shader 开工前,URP 会偷偷跑一个 Compute Shader,把屏幕切成小格子(Tiles),算出每个格子里到底只有哪几盏灯有效。 当 Fragment Shader 运行时,它会查表:“哦,我这个像素只受 2 号和 5 号灯影响”,然后只循环计算这 2 盏灯。这就是为什么 Forward+ 能支持几百盏灯的原因。
计算出的颜色直接通过深度测试,写入帧缓冲区 (Framebuffer)。
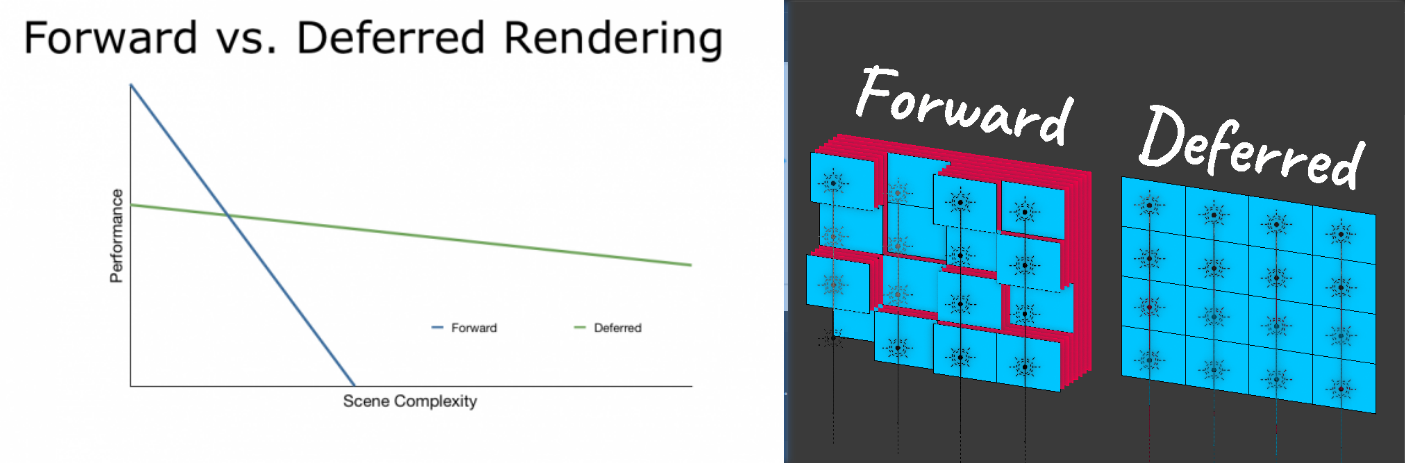
HDRP 默认使用 延迟渲染 (Deferred Rendering)。这是一种 “先记账,后结账” 的策略。
第一步:光照剔除 (Compute Shader)

在画任何东西之前,HDRP 先把屏幕切成无数个 16x16 的小格子 (Tiles)。利用 Compute Shader 的并行能力,算出每个格子里到底受哪几盏灯影响,生成一个列表。
第二步:填充 G-Buffer (几何阶段)
这里开始画物体。但注意!Fragment Shader 此时非常轻松,它不计算任何光照。 它只是把物体的属性(颜色、法线、粗糙度)像填表一样,填入到一组巨大的纹理中(G-Buffer)。
第三步:全屏光照计算
物体画完了,现在只剩下一张铺满屏幕的 G-Buffer。 HDRP 会画一个全屏的矩形,Fragment Shader 读取 G-Buffer 里的数据,结合第一步算好的光照列表,一次性把全屏幕的光照算出来。
UE5 基本上是在把 GPU 当作一个通用计算器在用,它是一个离经叛道的存在。
第一步:Nanite (网格处理)
传统的 Vertex Shader 灯在这里经常是不亮的。 Nanite 为了处理数亿个多边形,使用 Task Shader 和 Mesh Shader(甚至 Compute Shader 做软光栅)来动态处理网格簇 (Meshlets)。它彻底绕过了传统管线的前端瓶颈。
第二步:Lumen (全局光照)
在渲染的同时,后台并发跑着一套极其复杂的 Compute Shader。它们在追踪光线、计算间接光照(GI),然后把结果混合回主画面。
通过这个步进式的“仪表盘”视角,我终于明白:
所谓的 优化,其实就是一场关于“灯”的博弈:
Frag 灯亮的时间短一点(减少光照计算)。Frag 灯只算有效的像素(延迟渲染),但代价是显存带宽这盏灯更红了。Compute 灯重新造了一套轮子。搞清楚数据在每个阶段的状态,以前那些看着头大的渲染特性(Stencil, Blending, Tessellation),现在看来也不过是管线上的一个个小开关罢了。
No video available.